
Incident preparation
The defined incident response standards by NIST and SANS both begin with preparation, which includes having the required tools and logs before an incident occurs. It is an important part of incident response, and preparation is fed into and improved by the lessons learned from an incident response engagement. Below are key points for consideration during the preparation phase:
- Having the right level and volume of logging is important, including server event logs, authentication logs, endpoint AV logs, DHCP logs, Web proxy/DNS logs, and network security device/Firewall logs (this is a non-exhaustive list). This gives organisations a collections telemetry, ideally centrally collected while resting independent from source systems, for tracing and locating malicious behaviour, for historical lookup as well as alerting.
- Established policies for computer usage set the limits of acceptable use and secure behaviour. A policy should also inform users who to notify in the event they suspect an incident.
- Clear, defined definition of computer security incidents and prioritization levels.
- A clear communication plan is necessary for nominated members of the computer incident response team. As well as technical staff from the incident response team, the wider group should include management, legal, public relations, I.T, human resources, and local and national law enforcement contacts. Having an emergency contact list is beneficial for incident communications. This group needs a response strategy, incident prioritisation understanding, and impact measurement for senior management buy-in when handling large incidents. A nominated team member should be responsible for documentation of an incident. This will assist law enforcement where criminal acts have occurred.
- Up-to-date and accessible documentation of network infrastructure and critical assets.
- Structural I.T. components involved at this stage include having a defensive security architecture posture (i.e. defence in depth) and having a defined patch frequency for all I.T. systems.
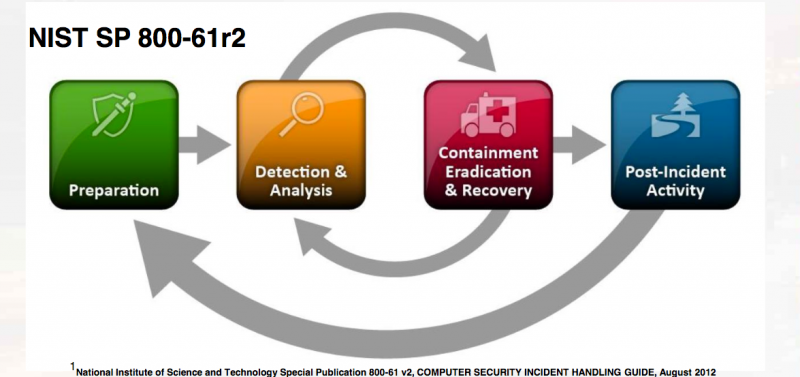
Incident detection and analysis
If a particular event is determined to be an incident, then "it should be reported as soon as possible to the Computer incident response team in order to allow the team enough time to collect evidence and prepare for the preceding steps" [3]. An incident such as an intrusion or malware outbreak should result in computer incident response team members being notified and communication coordinated between members.
This identification or analysis includes scoping an incident; defining the proportionate response to the impact of an incident and determining the appropriate scale of the investigation. Scoping should answer the question "what is the goal of the investigation" or "what is the desired outcome?".
In the event of an intrusion, the goal of an investigation would be to find when it occurred, where did it take place, and who/which account was abused to break in, what was accessed and why plus how did it happen (which vulnerability was exploited). p.84 [1] This guidance is known as the five W's and one H.
While determining the source of the attack or infection is often crucial, for investigation priorities it might be pertinent to ask, is the goal to find the vulnerable service, or find the attacker and prove their actions? For the incident timeline, did an intrusion or infection actually occur many months ago where the availability of log evidence might be reduced or unavailable? If during the investigation it becomes evident that P.I. information is lost or stolen, or accessed by an unauthorised user, legal teams would need to become involved in setting the scope, goal and reporting of the investigation, particularly if GDPR implications become a concern. "Reviewing the factors affecting the scale and goals of the investigation will help to set the expectations with management and should be communicated appropriately." p.92 [1]
After building a picture of the incident and then collecting and verifying the initial facts you will have a decent context for the incident. After this, gather additional preliminary evidence about those facts so you can establish context — IP address, host detail, and system role. The Computer Incident Response Team should be the gatekeeper standing between observed events and the investigation. As new information arrives, evaluate it with logic, common sense, and its relevancy to the incident. Ideally you should identify sources of evidence that come from several categories (such as those below) and require minimal effort to analyse p.120 [1]. Capture the attack time-line, locating the initial attack. Once the vector of attack and any spread/propagation is known, that information can be used to determine the course of action and how to contain the incident (described in the following 'containment' stage).
What to record
- Incident Summary checklist: The date an incident was reported, date incident detected, nature of incident, details of type of resources affected (such as PCI data, Intellectual property, student accounts or host system), unique identifiers and locations of the computers affected.
- Incident Detection detail checklist: Whether it was detected through automated process or manual discovery to assist checking validity, a copy of the detection alert if one exists, validation of source data accuracy or detection error rate, whether data is preserved before system purge or if there will be an automated rotation, any changes to the data sources or systems such as administrator tweaks, system upgrades or other maintenance, each system's primary function i.e. web server, and who is responsible for the end system.
- Additional Details: Host asset number, physical location. Who accessed the system since detection, operating system, primary function, responsible administrator, assigned IP, critical information stored, any remediation steps, whether backups exist, list of malware detected, still connected or isolated? If a user was involved has someone spoken with them and were they present on the machine.
- Network details: malicious IP or domain names involved, Whois checks, whether network monitoring is being performed, if so then check the associated filtering rules and data available. Up to date network diagrams.
- Any involved malware details, name of malicious file, directory it's in. Is it currently active, does it have active network connections that are present? Name of malware and family of malware detected. Has it been submitted to third parties automated or by employee. Current malware analysis status. Whether malware is preserved in quarantine or not?
What to inspect
This depends on the type of security incident, so below are some useful examples. Having multiple independent evidence sources will create a more reliable picture of a security incident and enable cross-checking on event times. Example sources of data:
Host and network transaction logs (server logs, client logs, website logs, proxy logs, netflow, firewall logs, mail headers, Syslog), authentication logs (A.D., Azure, Kerberos, Syslog), IDS/AV alerts, email attachments, device command history, IPs and domain names of involved hosts, DHCP logs, Active Directory/LDAP hostnames.
Malware events: file and registry key changes, application artefacts such as Internet browser history.
Intrusion events: changes to system configuration and services, unidentified network connections, greater memory and disk usage, lateral movement through inspection of network and authentication logs, and integrity checking to detect changes to files.
Large scale mail spread — mail headers including sender IP and initial SMTP server, message-ID, 5322 MailFrom source email address, and attachment payloads.
A final thought would be whether full digital forensics is needed in the scope of the investigation. The initial evidence gathered should help to scope the incident and help decide whether any forensic analysis is needed on the affected hosts. When considering forensic analysis, one should understand the end goal of the analysis, and the associated urgency level. Is it a direct hostile act or a scatter gun malware infection? A more in-depth analysis of malware can be achieved using forensic images to help identify the malware operating method, artefacts, and objectives (keylogger, remote shell, process privileges, etc). Further still, forensic analysis could also include security and network logfile analysis. A full digital forensics analysis, combing through a system disk or memory for malicious actions to a tight deadline, is an approach that demands dedicated forensic experts being called onto the scene. Time pressures must be considered; "..the time required for an investigation can affect the efficacy of the cybersecurity forensic professional to reconstruct and provide an accurate interpretation of the evidence." p.21 [2]
Incident containment
The containment and remediation plan must be based on the findings of the security team's investigation of the incident. The course of action to follow should be objective and ideally based on multiple independent sources of evidence from the analysis stage. "Containment provides time for developing a tailored remediation strategy." [4]. Decisions are easier to make if there are predetermined strategies, depending on the incident type, and incident containment procedures.
The team investigating an incident should develop an effective eradication plan and future prevention plan during the lessons learned phase. Listed below are some examples of possible incidents and associated containment actions:
- Identified ransomware or malware worm has been moving laterally using certain network services. Consider disabling unneeded host services to contain the spread and prevent further spread, i.e. SMBv1, Microsoft PSExec, LLMNR. Once the malware has been identified, generate hashes of the file(s) (MD5, SHA1, SHA256). Identify accounts used to install or execute files associated with the malware and review any installation and/or script logs on affected hosts.
- Large scale company-wide email phishing/malware delivery — extract the malicious emails that have common indicators: mail headers, source IP, message-ID, subject, URL, and attachment. Identify relevant IoCs and trace any historic activity on the network to known IoC domains or IPs. Any identified phishing pages/domains can be added to URL filtering solutions and/or RPZ files. If possible, update any antivirus products with known malicious file hashes.
- System or web compromise — freeze and snapshot ASAP the environment or system and isolate the network segment. Identify the system resources affected, timeline of activity, and movement of the attacker with network/firewall/system logs. Identify the vulnerability exploited to carry out the compromise, i.e. SQL injection or misconfigured service.
- Data exfiltration through account compromise. Piece together the incident timeline by reviewing file audit history logs, account logon and audit history, and network/firewall logs. Isolate affected systems, and preserve file data and timestamps without alteration for future analysis. Once the required evidence/information has been gathered from system and network log files, have the account owner interviewed by the appropriate authority.
- Network attack causing resource and bandwidth overload. Identify incoming target and associated source vector. Implement a mitigation such as dropping malicious packets at the edge of your network. Should you not be able to implement an edge mitigation without impacting your own network, contact CERT to arrange upstream mitigation.
Continued documentation of all actions taken will help gauge the cost of required resources and will assist in determining the overall impact of the incident to the organization. The focus of this article was on incident scoping and triage, however the eradication steps following containment would continue in the strategy delivered for containment but also including password resets, imaging, backup restore points and host security scanning tool usage. The incident completes the full life-cycle loop when the results of the investigation, containment, eradication and recovery feed back into the company security systems hardening and security preparedness. So it is intended a follow up piece covering eradication and lessons learned will be written to complete the overview.
Sources
- [1] Incident Response & Computer Forensics, McGraw Hill — J. Luttgens, M. Pepe, K. Mandia.
- [2] Cisco CCNA Cyber Ops SECOPS 210-255, Cisco Press — O. Santos, J. Muniz.
- [3] SANS Incident Handlers Handbook — sans.org
- [4] NIST Computer Security Incident Handling Guide — nvlpubs.nist.gov